Don’t like reading? Video accompaniment.
Fuzzy Sync
Fuzzy Sync is a library we have developed for the Linux Test Project (LTP). It allows us to synchronise events in time, thus triggering bugs which are dependant on the outcome of one or more data races. Additionally it can introduce randomised delays (the fuzzy part) to achieve outcomes that would otherwise be extremely rare.
Cyril Hrubis previously introduced the library on the kernel.org blog along with one of the tests we created it for. In this article I will present a contrived data race which demonstrates why a delay is sometimes needed in order to synchronise the critical sections.
Update: I extracted Fuzzy Sync from the LTP into a standalone library.
For reference the Fuzzy Sync library is just a single header file which you can see here. There is more documentation than code. It is entirely a user-land library, not tied to Linux in any way, although it does use a few other parts of the LTP library so it is not currently stand-alone. It certainly does not inject errors or delays into the kernel or instrument it.
Despite the fact I think this is an obvious thing to do, if you are writing an exploit or just writing regression tests involving a data race, I couldn’t find a library which already did it. Although I have since found various tools and whatnot with something similar embedded; for example the Syzkaller executor has system call collision.
Note that when I say ‘rare’, I mean rare in my local context. In the wild someone will accidentally (or deliberately for that matter) discover a way to trigger it on a regular basis. There are a lot of systems in the wild running a lot of different software.
The Race
We have a simple race between two threads A and B, trying to read and write to the same variable.
Let’s look at the race code, most of the boiler plate is omitted and just the main loops for threads A and B are shown along with some variable definitions. You can see the full source here.
static struct tst_fzsync_pair pair;
static volatile char winner;The data race revolves around the winner global
variable which we access in both threads. Roughly speaking;
setting it as volatile tells the compiler both that the value can
change at any time and also setting the value may have side effects.
In this case, it prevents the compiler from removing the
if statement in the code below. Static analysis will
show that winner is never equal to 'B'
unless the variable can change at any time.
pair contains the Fuzzy Sync libraries state and is
passed to most library functions. It is accessed from both threads
as well, but is protected with memory barriers and the atomic
API, which is far preferable to marking it as volatile.
Generally speaking, you shouldn’t just mark stuff as volatile and
then access it from multiple threads like any other variable.
However it makes the demo code easier to read and I’m only running
it on x86 so…
while (tst_fzsync_run_a(&pair)) {
winner = 'A';
tst_fzsync_start_race_a(&pair);
if (winner == 'A' && winner == 'B')
winner = 'A';
tst_fzsync_end_race_a(&pair);
}This is the loop for thread A,
tst_fzsync_run_a() returns true if the
test should continue and false otherwise.
tst_fzsync_start_race_a() and
tst_fzsync_end_race_a() delineate the block of code
where we think the race can happen. Usually this is just a single
statement, such as a function or system call, which is external to
our reproducer code. Usually we would have some more complex setup
between ...run_a/b() and
...start_race_a/b(), if we didn’t then it might be
better to dispense with Fuzzy Sync and just use a pair of plain
loops. Which is actually the case here, but for now let’s just
pretend something complex and time consuming needs to be done before
each race.
Before the race begins we set winner to
A, then during the race we branch on the seemingly
impossible condition
winner == 'A' && winner == 'B'`Clearly if winner is 'A' then it is not
'B', unless the value of winner changes
half way through the statement. Which it can because this is
actually two statements in C and will be compiled to a number of
assembly instructions. In other words it is not atomic.
0x00000000004055d2 <+1026>: movzbl 0x1b297(%rip),%eax # 0x420870 <winner>
0x00000000004055d9 <+1033>: cmp $0x41,%al
0x00000000004055db <+1035>: je 0x4057e8 <run+1560>
... <500+ lines of fuzzy sync assembly redacted> ...
0x00000000004057e8 <+1560>: movzbl 0x1b081(%rip),%eax # 0x420870 <winner>
0x00000000004057ef <+1567>: cmp $0x42,%al
0x00000000004057f1 <+1569>: jne 0x4055e1 <run+1041>
0x00000000004057f7 <+1575>: movb $0x41,0x1b072(%rip) # 0x420870 <winner>
0x00000000004057fe <+1582>: jmpq 0x4055e1 <run+1041>This is the x86_64 assembly which checks and sets
winner. The first 2 instructions load
winner and compare it to 'A', the third
will then jump to the second half of the statement if it is equal to
'A'. The second half is much like the first.
Importantly we have two loads on winner (the two
movzbls) which chronologically happen a few
instructions apart.
Interestingly GCC has decided to move the second half of the
statement towards the end of the program. I guess this is related to
some CPU instruction cache optimisation, hint to branch prediction,
register juggling or something else. If the behavior of our program
is dependant on a data race, then this kind of optimisation
can have a significant effect on the program behavior. A data race
outcome which is highly improbable if the kernel is compiled with
one compiler version may be highly probable when compiled with
another. In this particular case, it won’t make a difference because
the timings are dominated by nanosleep.
struct timespec delay = { 0, 1 };
while (tst_fzsync_run_b(&pair)) {
tst_fzsync_start_race_b(&pair);
nanosleep(&delay, NULL);
winner = 'B';
tst_fzsync_end_race_b(&pair);
}We have a similar loop for thread B, the big
difference is we make a system call and just set winner
to 'B'. nanosleep here will attempt to
sleep for one nanosecond, which basically means it won’t sleep at
all as context switching takes far longer than a nanosecond, so by
the time it gets into kernel land it will have already spent too
long.
In a real test we usually have one or more syscalls in A and B. The race happens somewhere deep in the kernel and all we can do is ‘collide’ the system calls. Possibly one thread’s system calls may take much longer to reach the race critical section than the other. This is what we are simulating here; we have a very large difference in the time it takes A to reach the race critical section compared to B.
To make matters worse the race window is very short relative to
the time it takes to context switch in and out of the kernel. We
could move the sleep to before tst_fzsync_start_race_b,
but often in a real reproducer the ideal place to demarcate the race
window is somewhere inside the kernel.
Visualising the race
The race has been run 100,000 times and timestamps taken of when
A and B start and finish. The
differences between A and B are
shown below. The red circle indicates where A won
the race, that is, set winner = 'A'. In this case
A only won once.
Each time difference is represented by a small black dot.
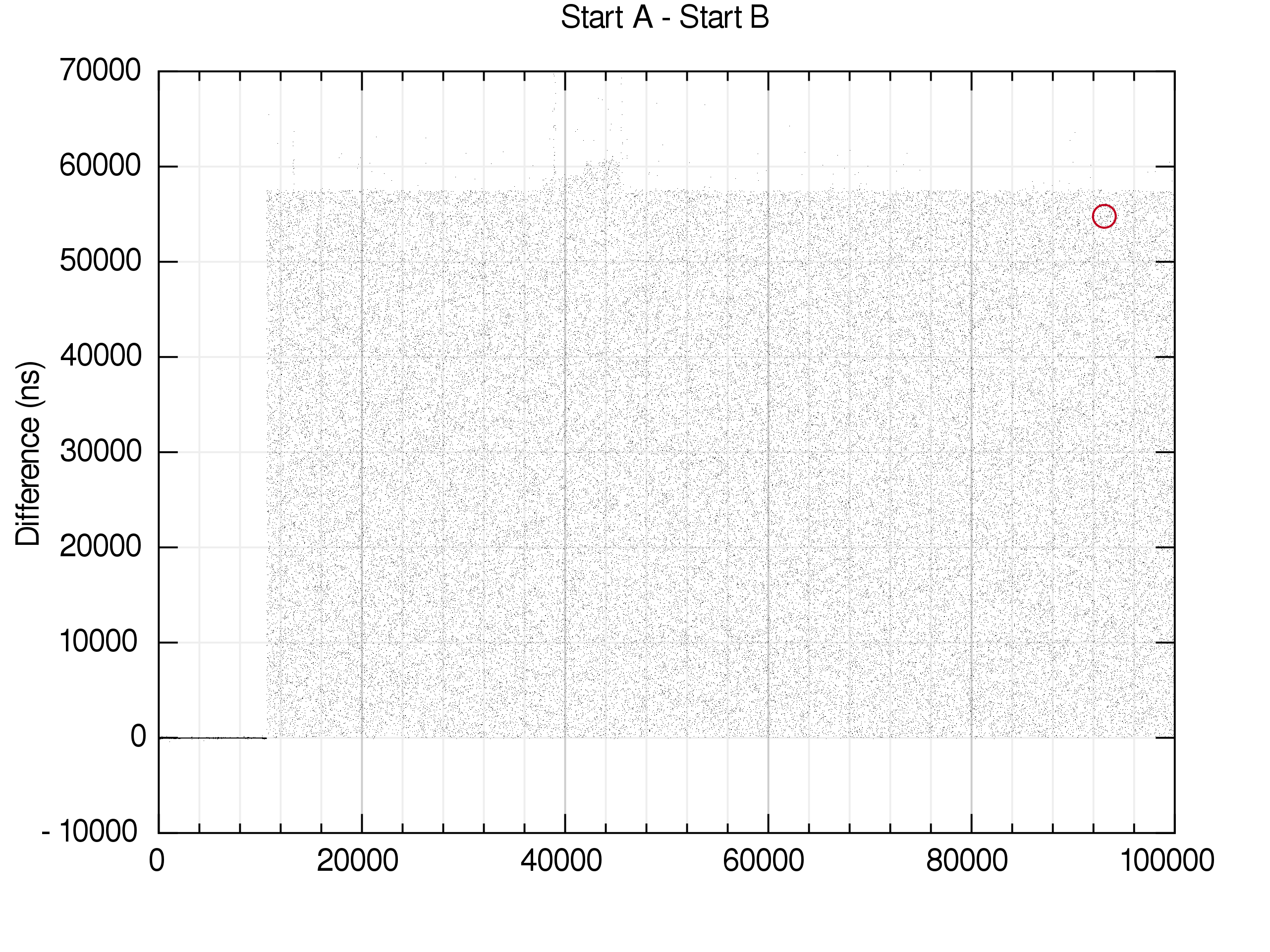
That is the time difference between when A
exited tst_fzsync_start_race_a() and when
B exited tst_fzsync_start_race_b().
Initially both A and B start at
about the same time; after about ~13000 loops the random delay of
A is introduced.
Strictly speaking, the possible delay range includes a small delay to B as well, so that A ends as B starts, but A is so short we can’t see it on this graph.
You can see that when the start of B is delayed enough we may hit the race condition. It is close to the upper bound of the delay range.
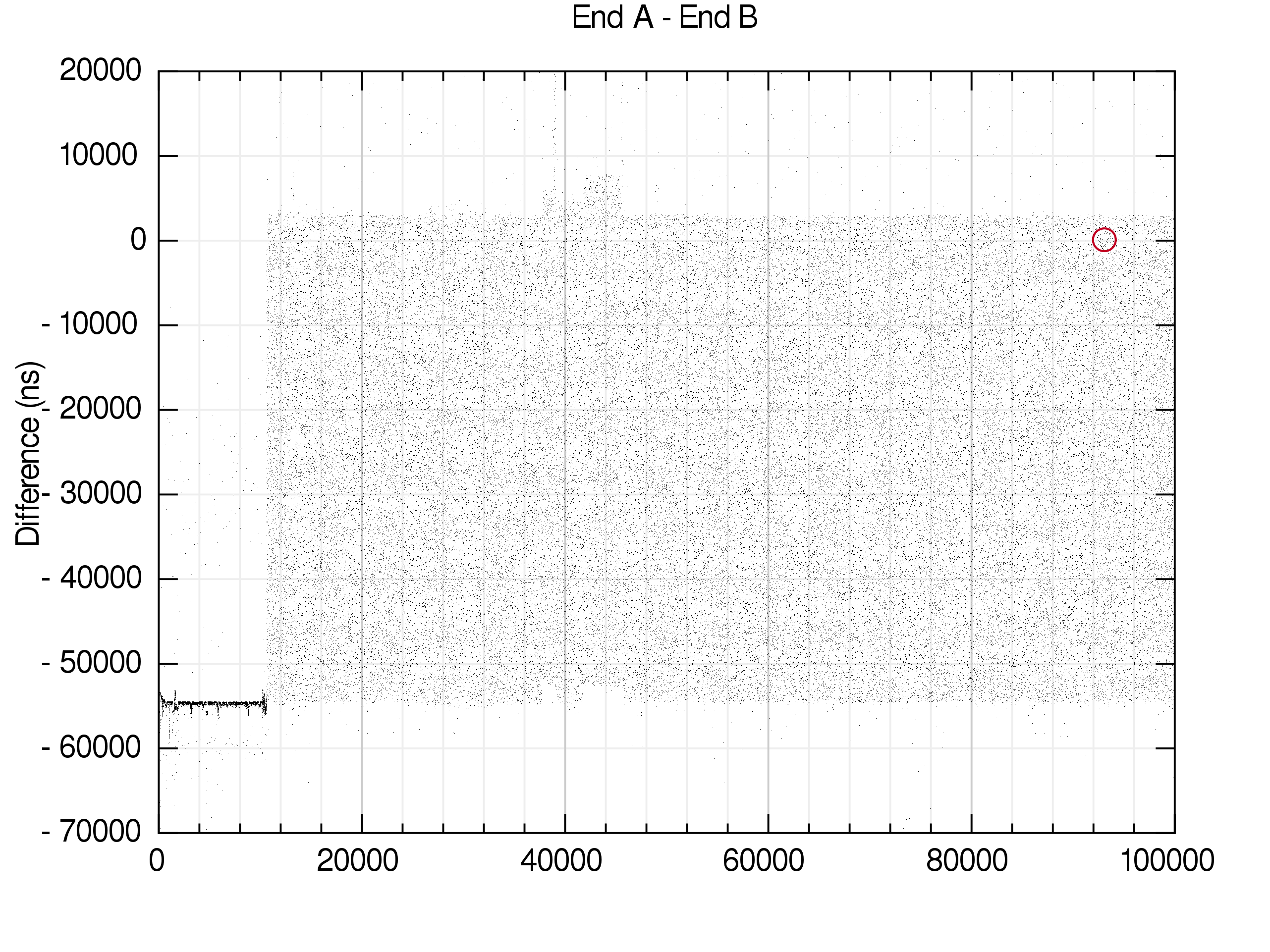
On the left of this graph we can see that B is consistently ~55000 nanoseconds behind A by the finish. If you look very closely you will find outliers where this is not the case, but we would have to rerun the race for a long time for A to win (on my setup).
The delay is calculated once a minimum number of loops have been completed and the mean deviation of various timings settles down. On the left you can see there is some natural jitter, but not much relative to the overall difference in end times. So the delay is calculated after relatively few loops. If the natural jitter were relatively large, then we wouldn’t need to artificially introduce more.
Once the delay is introduced we can see that A and B are far more likely to finish at the same time. The race window for A to win is almost precisely at a difference of 0.
Visualising the race 2
Below is a more abstract (and patently not-to-scale) visualisation of the two major epochs of Fuzzy Sync execution.

In the first case we are just using spin locks which act as
synchronising barriers for entering and exiting the race (see
tst_fzsync_pair_wait() in the code).
When one thread reaches the end of the race before the other, it counts the number of times it spins waiting. We use this value later to calculate the delay range.
The second diagram shows the ideal delay for 'A' to
win the race, however we actually calculate a delay range and
randomly pick values from it. In this example we know exactly where
the race occurs so we could dispense with some of the stochasticity
and narrow the delay range to just attempt the synchronisation
shown.
However, for most tests, we don’t have this level of knowledge about the race condition on all possible kernel versions and configurations where the bug exists. In fact we sometimes don’t know much at all about the call tree and timings within the kernel, we just know that calling syscall X and Y at the same time makes bad things happen.
For an attacker focusing on a particular system though, you can
assume that they would be able to narrow the delay range down to a
value which allows them to trigger the race in much fewer
iterations. Fuzzy Sync allows this in some cases using
tst_fzsync_pair_add_bias() which I may cover in a
future article.
Reproducers using Fuzzy Sync
At the time of writing there are several LTP tests using Fuzzy Sync:
- cve-2014-0196
- cve-2016-7117
- cve-2017-2671
- pty03 (cve-2020-14416)
- snd_seq01 (cve-2018-7566)
- snd_timer01 (cve-2017-1000380)
- bind06 (cve-2018-18559)
- inotify09
- shmctl05
- sendmsg03 (cve-2017-17712)
- setsockopt06 (cve-2016-8655)
- setsockopt07 (cve-2017-1000111)
- timerfd_settime02 (cve-2017-10661)
- fanout01 (cve-2017-15649)